선형 회귀란 무엇인가
머신 러닝의 주요 목표는 실제 데이터를 기반으로 모델을 구축하여 다른 입력 값에 대한 출력을 예측하는 것이다.
이를 위해 가장 직관적이고 간단한 모델을 선형모델이다.
선형 회귀 분석은 주어진 데이터를 가장 잘 설명하는 선을 찾는 분석 방법이다.
예를 들어 키와 몸무게 데이터를 수집하여 그것들을 가장 잘 설명하는 선을 찾으면 해당 선을 기반으로 특정 개인의 키를 사용해 몸무게를 예측할 수 있다.

머신 러닝에서 선형 회귀는 종속 변수(예측하려는 변수_몸무게)와 한 개 이상의 독립 변수(영향을 주는 변수_키, 성별 등) 간의 선형적인 관계를 모델링 하는 것을 목표로 한다. 이를 위해 주어진 데이터에 적합한 회귀선을 찾기 위해 최소제곱법*을 사용해 회귀 계수를 추정한다.
* 선형 회귀에서 최소제곱법을 적용할 때는 평균제곱오차(MSE)를 최소화하는 회귀 계수를 찾는 것이 목표이다.
- MSE(평균제곱오차) : 선형 회귀에서 주로 쓰인다. 선형 회귀에서 최소제곱법은 MSE를 최소화하는 방법이다. 예측값과 실제 값 사이의 제곱 오차의 평균이다.
이외에도 손실 함수의 종류는 많다.
- MAE : 예측값과 실제 값의 차이인 오차들의 절대값 평균
- RMSE : MSE에 루트를 취해 준 것, RMSE는 예측값과 실제 값 사이의 제곱 오차의 평균의 제곱근
머신러닝과 같은 예측모델을 위해서는 변수에 대한 분석이 중요하다.
선형회귀분석은 변수 간 관계를 모델링하고 추론하는데 사용되는 통계적 방법 중 하나이다.
선형회귀모델은 종속변수와 독립변수 사이의 최적의 선형 관계를 찾기 위해 회귀 계수(가중치)를 추정한다.
이를 위해서 변수 간 관계를 분석하고 시각화하는 과정을 알아보겠다.
1. 필요한 라이브러리 가져오고 경고 메세지 필터링하는 역할
import pandas as pd #Analysis
import matplotlib.pyplot as plt #Visulization
import seaborn as sns #Visulization
import numpy as np #Analysis
import tensorflow as tf #신경망 모델을 구축하고 학습
from sklearn.preprocessing import MinMaxScaler #데이터를 최소값과 최대값으로 스케일링
from sklearn.preprocessing import StandardScaler #평균과 표준편차 사용해 데이터를 표준화
import warnings #경고모듈
warnings.filterwarnings('ignore') #경고 메시지를 무시하도록 설정
%matplotlib inline #주피터노트북 등 환경에서 그래프를 출력하기 위한 매직 명령어
color = sns.color_palette() #seaborn의 컬러팔레트 생성해 color변수에 저장
#그래디언트 부스팅 알고리즘을 기반으로 한 머신러닝 라이브러리->효율적인 속도와 예측 성능
from lightgbm import LGBMRegressor
#그래디언트 부스팅 알고리즘을 기반으로 한 머신러닝 라이브러리->고성능 예측모델 구축
from xgboost import XGBRegressor
!pip install eli5
#explain like I'm 5 의 약자 = 머신 러닝 모델의 설명 가능성을 높이는 도구
import eli5
#eli5의 일부로 모델의 변수 중요도를 평가하기 위해 변수를 무작위로 섞고 성능에 대한 영향 측정
from eli5.sklearn import PermutationImportance
2. 데이터 정규화
- 데이터마다 분포가 다양하고 최대값과 최소값의 범위가 다르기 때문에 정규화는 중요하다.
#데이터 스케일링 (preprocessing) 정규화
min_max_scaler = MinMaxScaler()# MinMaxScaler 객체를 생성하여 min_max_scaler 변수에 할당
min_max_scaler.fit(train)# fit 메서드를 호출해 주어진 데이터셋(train)에 대해 스케일링 파라미터(최솟값, 최댓값) 추정
# 최소값과 최대값을 이용해 정규화된 값으로 변환, 이를 output에 저장
output = min_max_scaler.transform(train)
#정규화된 데이터를 데이터프레임 형태로 변환, 기존 train데이터프레임과 동일한 열,인덱스를 가지도록
output = pd.DataFrame(output, columns=train.columns, index=list(train.index.values))
#누락된 값이 있는 행 제거
output = output.dropna(0)
print(output.head())위의 코드를 출력한 형태 (.head() = 데이터프레임의 첫 5개 행 출력)
3. 설정하기
plt.rcParams["figure.facecolor"] = 'w' #그래프의 배경을 흰색으로
plt.rcParams['axes.unicode_minus'] = False #그래프 축의 음수 기호를 올바르게 표시하기 위해
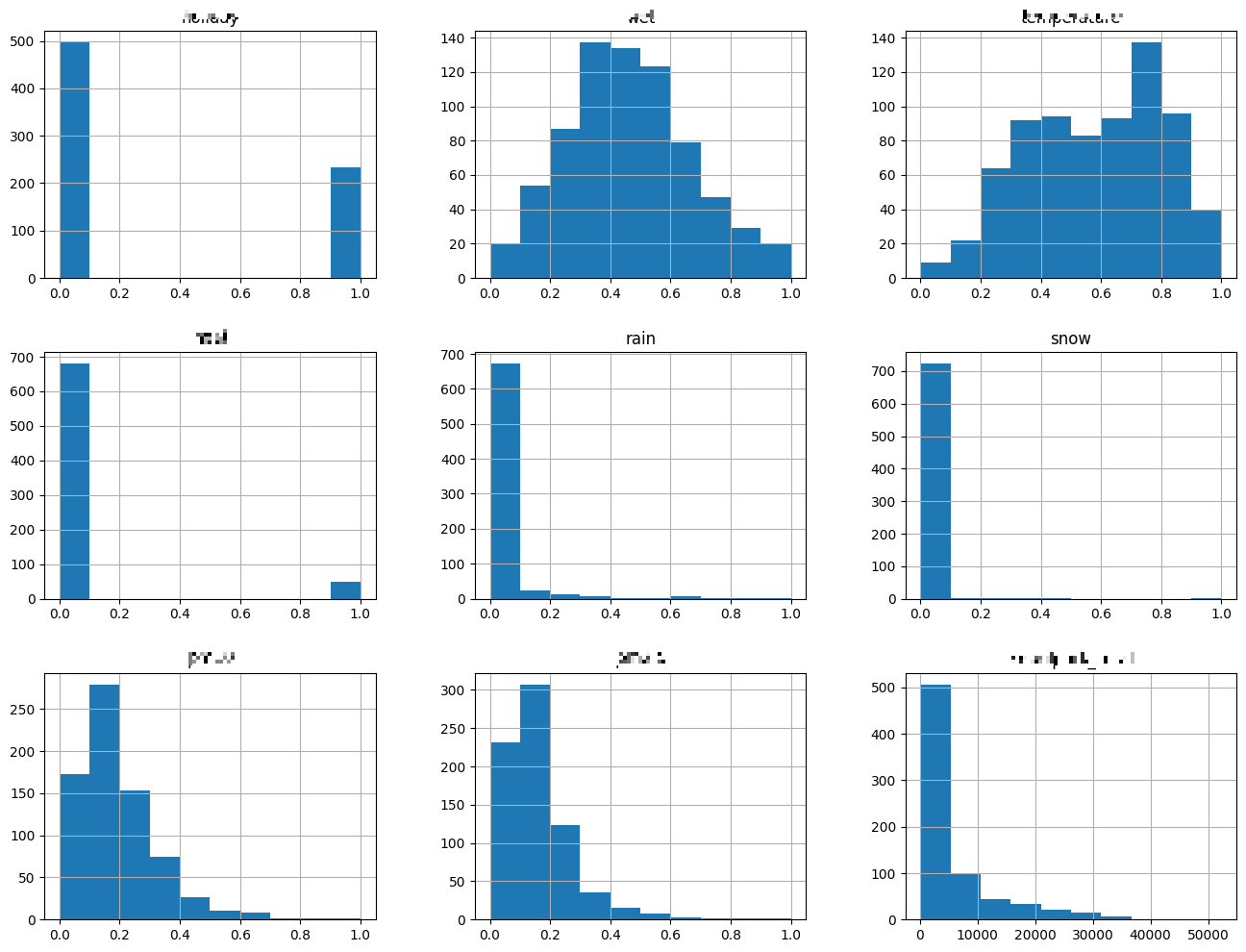
4. 히스토그램 : output 데이터 프레임의 각 열에 대해 히스토그램을 생성하여 시각화
- 히스토그램 : 한 개 변수에 대한 몇 가지 데이터 포인트의 빈도 분포를 나타내는 데 사용되는 그래프
output.hist(figsize = (16, 12))
plt.show()
위의 코드 실행 부분
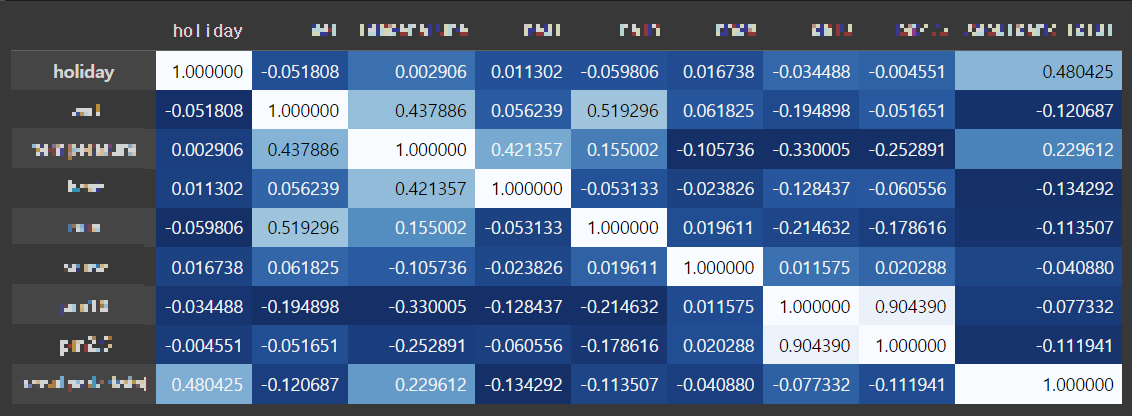
5. corr : output 데이터프레임의 열 간 상관관계 계산 후 계산된 상관계수 시각화
- corr() 함수는 열 간 상관계수를 계산하여 반환
- .style로 스타일 지정, .background_gradient()함수를 호출하여 배경 그라디언트 설정, cmap으로 색상 맵 이용
output.corr().style.background_gradient(cmap='Blues_r')위의 코드 실행 부분
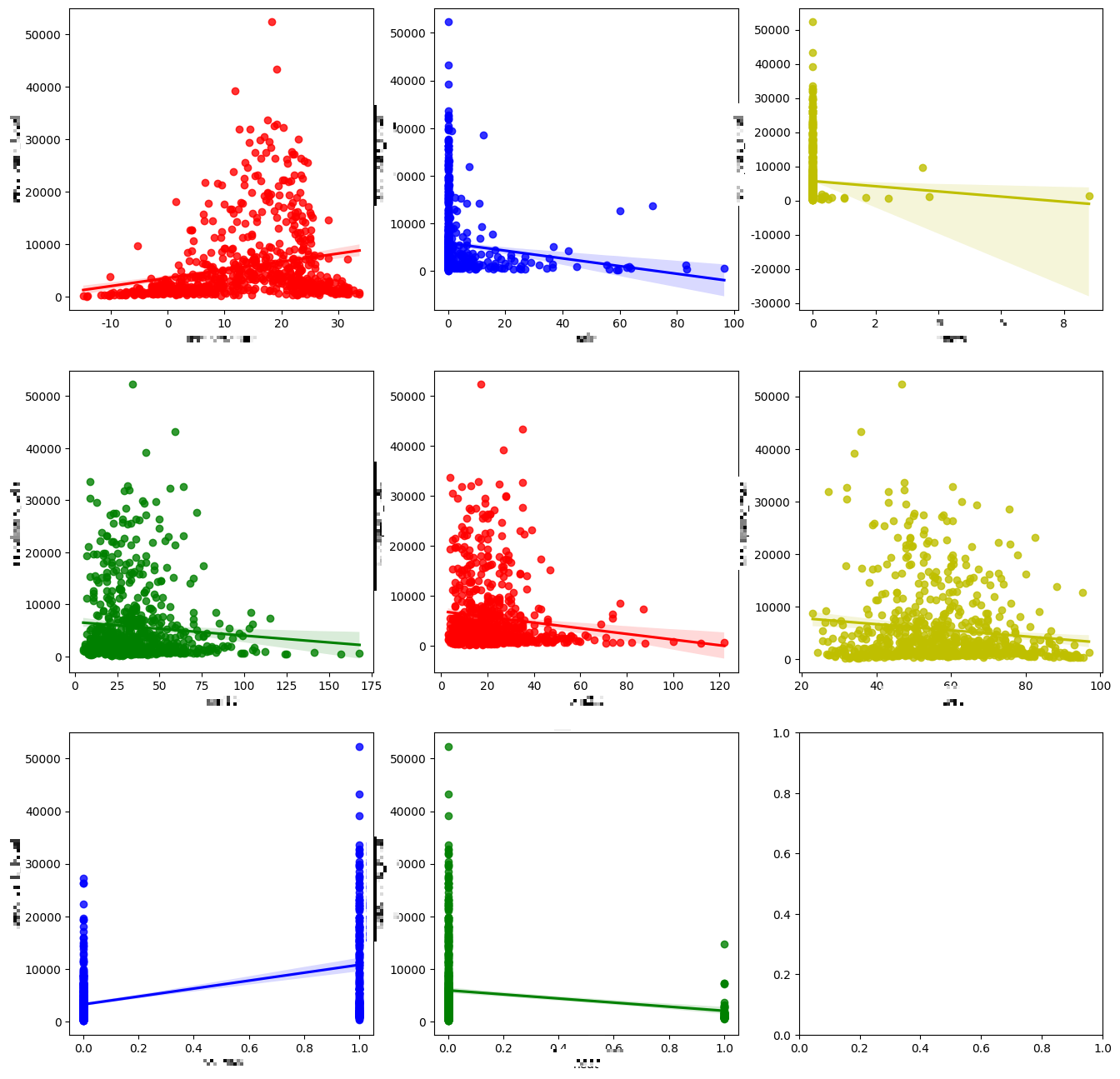
6. 회귀선 그래프
x_features로 x축에 들어갈 변수들을 지정한다.
y에는 하나의 변수만을 지정한다.
즉 나의 데이터셋에서 x축에 들어갈 속성을 지정하고 y축에 들어갈 속성을 지정하여 변수마다 y축과의 관계를 보여주는 그래프를 그린다.
fig, axs = plt.subplots(figsize = (16, 16), ncols = 3, nrows = 3)
x_features = ['a', 'b', 'c',
'd', 'a_2', 'b_2', 'c_2', 'd_2'] #x축에 들어갈 변수들, 데이터셋에 저장된 열 이름으로 해야한다.
plot_color = ['r', 'b', 'y', 'g', 'r', 'y', 'b', 'g'] #색 지정
for i, feature in enumerate(x_features):
row = int(i/3)
col = i%3
sns.regplot(x=feature, y='total', data = train,
ax = axs[row][col], color = plot_color[i])
#x축에 들어갈 변수 각각과 y축의 선형관계를 보여준다.