4.1 훈련데이터와 시험데이터
범용 능력을 제대로 평가하기 위해 훈련 데이터와 시험 데이터의 분리가 필요
데이터셋 하나로만 매개변수의 학습 및 평가를 수행하면 올바른 평가가 될 수 없음
* 오버피팅 문제 : 한 데이터셋에만 지나치게 최적화된 상태
- 훈련 데이터만 사용하여 학습해 최적의 매개변수 찾음
- 그 후 시험 데이터를 사용하여 훈련한 모델의 실력을 평가함
4.2 손실함수
- 신경망은 하나의 지표를 기준으로 최적의 매개변수 값을 탐색함
: 신경망 학습에서 사용하는 지표를 손실 함수라고 한다.
1) 오차제곱합
- 가장 많이 쓰이는 손실함수

y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] #정답만 1임=원핫인코딩배열들의 원소는 첫 번째 인덱스부터 숫자 0, 1, 2, 3 ...이다.
y는 소프트맥스 함수의 출력이다. (소프트맥스 함수의 출력은 확률로 해석할 수 있다.)
그러므로 이미지가 '0'일 확률은 0.1, '1'일 확률은 0.05, '2'일 확률은 0.6이다.
t는 정답레이블이다. '2'에 해당하는 원소의 값이 1이므로 정답은 '2'임을 알 수 있다.
파이썬 구현
import numpy as np
# MSE 함수 구현_오차제곱합
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
# 정답이 2일때
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
# ex) 2일 확률이 가장 높다고 했을 때
y = [0.1,0.2,0.6,0.0,0.05,0.02,0.0,0.0,0.0,0.03]
sum_squares_error(np.array(y), np.array(t))
#출력 : 0.10690000000000004
------------------------------------------------------
# ex2) 5일 확률이 가장 높다고 했을 때
y = [0.1,0.2,0.05,0.0,0.5,0.1,0.05,0.0,0.0,0.0]
sum_squares_error(np.array(y), np.array(t))
#출력 : 0.6075손실 함수의 출력이 작을수록 정답에 가까울 것으로 판단 가능
2) 교차엔트로피 오차
- 정답에 해당하는 출력이 커질수록 0 에 접근하다가, 그 출력이 1일 때 0이 된다.
반대로 정답일 때의 출력이 작아질수록 오차는 커진다.

def cross_entropy_error(y, t):
delta = 1e-7 # log함수에 0을 입력하면 -inf 출력되므로 이를 막기위해 아주 작은 값 더해줌
return -np.sum(t * np.log(y + delta))
# 정답이 2일때 (0.6의 확률로 2라고 예측)
y = [0.1,0.2,0.6,0.0,0.05,0.02,0.0,0.0,0.0,0.03]
cross_entropy_error(np.array(y), np.array(t))
#출력 : 0.510825457099338
# 정답이 2일때 (0.6의 확률로 7이라고 예측)
y = [0.1,0.05,0.1,0.0,0.05,0.1,0.0,0.6,0.0,0.0]
cross_entropy_error(np.array(y), np.array(t))
#출력 : 2.3015840929945458손실함수의 출력이 작을수록 정답에 가까울 것으로 판단할 수 있음 (오차제곱합의 판단과 일치)
4.3 미니배치
훈련 데이터 모두에 대한 손실함수의 합을 구하는 방법

N으로 나눔으로써 평균손실함수를 구한다. 모 든 데이터를 대상으로 손실함수의 합을 구할 경우 많은 시간이 소요된다.
빅데이터 수준이 되는 경우 데이터 일부를 추려 전체의 근사치로 이용할 수 있다. 이 일부를 미니배치라고 한다.
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True,
one_hot_label=True)
# 무작위로 10장 빼내기
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]* np.random.choice(60000,10) #0이상 60000미만 수 중 무작위로 10개 고르기
4.4 (배치용)교차 엔트로피 오차 구현하기
미니배치 같은 배치 데이터를 지원하는 교차 엔트로피 오차를 구현하는 방법
#데이터가 하나인 경우 구현
def cross_entropy_error(y, t) :
if y.ndim == 1: #y가 1차원일 경우 (데이터 하나씩 구하는 경우)
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t*np.log(y + 1e-7)) / batch_size
y는 신경망의 출력, t는 정답 레이블
y가 1차원인 경우(데이터 하나당 교차 엔트로피 오차를 구하는 경우)는 reshape함수로 데이터의 형상 바꿔줌
그리고 배치의 크기로 나누어 정규화하고 이미지 1장당 평균 교차 엔트로피 오차를 계산
#정답레이블이 원핫인코딩이 아닌 경우('2'나 '7'등의 숫자 레이블로 주어졌을 때) 구현
def cross_entropy_error(y, t) :
if y.ndim == 1: #y가 1차원일 경우 (데이터 하나씩 구하는 경우)
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t*np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size원핫 인코딩일 때는 t가 0인 원소는 교차 엔트로피 오차도 0이므로 그 계산은 무시해도 좋다.
즉 정답에 해당하는 신경망의 출력만으로 교차엔트로피 오차를 계산할 수 있다.
np.log(y[np.arange(batch_size), t]) : np.arange(batch_size)은 0부터 batch_size-1까지 배열 생성, t에는 레이블이 [2,7,0,9,4]와 같이 저장되어 있으므로 y[np.arange(batch_size), t]는 각 데이터의 정답 레이블에 해당하는 신경의 출력을 추출
예) t = [2,7,0,9,4] 일 때, [y[0,2], y[1,7], y[2,0], y[3,9], y[4,4]]인 넘파이 배열 생성
4.5 왜 손실함수를 설정할까?
정확도라는 지표를 놔두고 손실함수의 값이라는 우회적인 방법을 택하는 이유가 무엇일까?
미분의 역할에 주목.
매개변수의 손실함수의 미분이란 '가중치 매개변수의 값을 아주 조금 변화시켯을 때, 손실함수가 어떻게 변하나'라는 의미.
- 매개변수의 미분(기울기)을 계산하고, 그 값을 단서로 매개변수의 값을 서서히 갱신하는 과정 반복
- 미분 값의 양,음에 따라 반대방향으로 매개변수 변화시켜 손실함수 값 줄일 수 있음
- 미분 값이 0이 되면 가중치 매개변수의 갱신이 멈춘다. = 가중치 매개변수를 어느쪽으로 움직여도 손실함수의 값은 줄어들지 않기
정확도를 지표로 삼으면 매개변수의 미분이 대부분의 장소에서 0이된다
- 매개변수의 값을 미세하게 조정시켜도 연속적인 변화가 아닌 불연속적인 띄엄띄엄한 값으로 바뀜
- 매개변수의 미소한 변화에는 거의 반응을 보이지 않음, 반응이 있더라도 그 값이 불연속적으로 갑자기 변화함
- 계단함수를 활성화함수로 사용하지 않는 것과 같은 이유
시그모이드 함수의 미분은 어느 장소라도 함수의 미분(기울기)은 0이 되지 않는다. 신경망의 중요한 성질이며 이 덕분에 신경망이 올바르게 학습된다.

4.6 수치미분
1) 미분
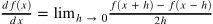
10분에 2km를 달렸다고 했을 때
- 10분 동안의 '평균속도'를 구한 것
- 시간을 가능한 한 줄여 '한 순간'의 변화량을 얻는 것이 미분(어느 순간의 속도)
- 시간을 뜻하는 h를 한없이 0에 가깝게 한다는 의미로 lim로 나타냄
나쁜 예인 이유
- h에는 가급적 작은 값 대입하고 싶어 (0에 가까이 하고싶어) 너무 작은 값 사용 : 반올림 오차문제(작은값 생략) --> 10e-4사용
- 진정한 미분은 x위치의 함수의 기울기에 해당, 그러나 f(x+h)와 f(x)사이의 차는 엄밀히 이와 일치하지는 않음. 이 차이는 h를 0으로 무한히 좁히는 것이 불가능하여 나타나는 한계다.
수치미분 다시 구현
# 두 개선점 적용해 수치미분 다시 구현
def numerical_diff(f,x):
h = 1e-4
return (f(x+h) - f(x-h)) / (2*h)
4.7 수치미분의 예
# 2차 함수 구현하기
def function_1(x):
return 0.01*x**2 + 0.1*x
# 함수 그려보기
import matplotlib.pyplot as plt
x = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.plot(x,y)
plt.show()
x가 5일때와 10일 때 이 함수의 미분 계산
print(numerical_diff(function_1, 5))
print(numerical_diff(function_1, 10))
#출력: 0.1999999999990898
#출력: 0.2999999999986347- x가 5와 10일때 완벽한 미분은 0.2와 0.3
- 오차가 매우 적어 거의 같은 값이라고 할 수 있음
4.8 편미분
f(x0, x1) = x0^2 + x1^2
변수가 두개 존재한다.
파이썬으로 구현
#파이썬 구현
def function_2(x):
return x[0]**2 + x[1]**2 # 또는 return np.sum(x**2)
이를 미분할 때 변수가 2개이기 때문에 어느 변수에 대한 미분이냐를 구별해야한다.
이와 같이 변수가 여럿인 함수에 대한 미분을 편미분이라고 한다.
편미분 문제 예시
- 문제1 : x0=3, x1=4일때, x0에 대한 편미분 af/ax0를 구하라
def function_tmp1(x0):
return x0*x0 + 4.0**2.0
numerical_diff(function_tmp1, 3.0)
#출력: 6.00000000000378편미분을 푸는 방법
- 변수가 하나인 함수를 정의
- 그 함수를 미분
편미분은 변수가 하나인 미분과 마찬가지로 특정 장소의 기울기를 구한다.
대신, 여러 변수 중 목표 변수 하나에 초점을 맞추고 다른 변수는 값을 고정한다.
4.9 기울기
x0과 x1의 편미분을 동시에 계산하고 싶다면?
기울기 필요함.
기울기 : (af/ax0, af/ax1)처럼 모든 변수의 편미분을 벡터로 정리한 것
# 기울기 구현
def numerical_gradient(f, x): #f는 함수이고 x는 넘파이 배열이므로 배열x의 각 원소에 대해 수치미분 구함
h = 1e-4
grad = np.zeros_like(x) # x와 형상이 같고 그 원소가 모두 0인 배열
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 계산
x[idx] = tmp_val + h
fxh1 = f(x)
#f(x-h) 계산
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 값 복원
return gradprint(numerical_gradient(function_2, np.array([3.0, 4.0])))
print(numerical_gradient(function_2, np.array([0.0, 2.0])))
print(numerical_gradient(function_2, np.array([3.0, 0.0])))
#출력:
#[6. 8.]
#[0. 4.]
#[6. 0.]
- 기울기의 결과에 마이너스를 붙인 벡터 그리기
- 그림의 기울기는 함수의 가장 낮은 장소(최솟값)를 가리킴
- 그림처럼 반드시 기울기는 가장 낮은 장소를 가리키는 것은 아님
- 기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장크게 줄이는 방향
4.10 경사하강법
기울기를 이용해 함수의 최솟값(또는 가능한 한 작은 값)을 찾으려는 것이 경사법.
- 주의할 점 : 각 지점에서 함수의 값을 낮추는 방안을 제시하는 지표가 기울기라는 것
- 기울기가 가리키는 곳에 정말 함수의 최솟값이 있는지 보장할 수는 없음
- 실제로 복잡한 함수에서는 기울기가 가리키는 방향에 최솟값이 없는 경우가 대부분
경사법은 현 위치에서 기울어진 방향으로 일정 거리만큼 이동한다. 그 다음 그곳에서 기울기를 구하고 또다시 그 기울어진 방향으로 나아가기를 반복한다.

n기호(에타)는 갱신하는 양 (학습률) : 한번의 학습으로 얼만큼 학습해야 할지, 즉 매개변수 값을 얼마나 갱신하느냐를 정하는 것이 학습률이다.
위 식은 변수가 2개인 경우로 1회에 해당하는 갱신이다. 이를 반복하여 변수의 값을 갱신해 서서히 함수의 값을 줄여나가면 된다.
# 경사법 구현
# f는 구현함수 / init_x는 초깃값 / lr은 학습률 / step_num은 반복 횟수
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
# 경사법으로 f(x0, x1)= x0^2+x1^2의 최솟값 구하기
def function_2(x):
return x[0]**2 + x[1]**2
init_x = np.array([-3.0, 4.0]) # 초깃값 설정
gradient_descent(function_2, init_x=init_x, lr=0.1, step_num=100)
출력: array([-6.11110793e-10, 8.14814391e-10])
#실제 정답인 (0,0)에 가까운 결과 도출
학습률을 적절히 설정하는 것이 중요하다.
- 학습률이 너무 클 경우 최솟값을 찾지 못하고 건너뛸 수 있음.
- 학습률이 너무 작을 경우 거의 갱신되지 않은 채 반복 종료될 수 있음.
* 학습률 같은 매개변수를 하이퍼파라미터라고 한다.
- 사람이 직접 설정하는 매개변수
- 여러 후보값 중에서 시험을 통해 가장 잘 학습하는 값을 찾는 과정을 거쳐야 한다.
4.11 신경망에서의 기울기
신경망 학습에서도 기울기를 구해야한다. 여기서의 기울기는 가중치 매개변수에 대한 손실 함수의 기울기이다.

ex) 형상이 2X3, 가중치가 W, 손실함수가 L인 신경망 (경사는 aL/aW)
aL/aW의 각 원소는 각각의 원소에 대한 편미분
aL/aW의 형상은 W와 같음
simpleNet클래스
형상이 2*3인 가중치 매개변수 하나를 인스턴스 변수로 가짐.
메서드는 2개로, 예측 수행하는 predict(x)와 손실 함수의 값을 구하는 loss(x,t) 이다. 인수x는 입력데이터, t는 정답 레이블이다.
import sys, os
sys.path.append(os.pardir)
import numpy as np
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
class simpleNet:
def __init__(self):
self.W = np.random.randn(2, 3) # 정규분포로 초기화
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss# simpleNet 활용해보기
net = simpleNet()
print(net.W) # 가중치 매개변수
#출럭: [[ 0.12494685 0.5020375 -0.92335954]
# [-0.01197582 0.60362506 -0.95622184]]
x = np.array([0.6, 0.9])
p = net.predict(x)
print(p)
#출력: [0.06418987 0.84448505 -1.41461538]
print(np.argmax(p)) #최댓값의 인덱스
#출력: 1
t = np.array([0, 0, 1]) # 정답레이블
net.loss(x, t)
#출력: 2.705523700978955# 기울기구하기
# 함수의 인수 W는 더미로 만든 것 / numerical_gradeint(f, x) 내부에서 f(x)를 실행하는데,
# 그와의 일관성을 위해 정의
def f(W):
return net.loss(x, t)
dW = numerical_gradient(f, net.W)
print(dW)
#출력:
#[[ 0.17595147 0.38394657 -0.55989803]
# [ 0.2639272 0.57591985 -0.83984705]]기울기 해석
- 0.1759...의 첫번째 기울기는 w11을 h만큼 늘리면 손실 함수의 값은 0.17h만큼 증가한다는 의미
- -0.83...의 마지막 기울기는 w23을 h만큼 늘리면 손실함수의 값은 0.83h만큼 감소한다는 의미
- 즉, 손실함수를 줄인다는 관점에서는 w23은 양의 방향으로, w11은 음의 방향으로 갱신해야함
- 기울기 값이 클수록 갱신되는 양에 크게 기여
# lambda 기법 사용하면 더 편리하게 구현가능 (간단한 함수의 경우만 사용)
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)신경망의 기울기를 구한 다음에는 경사법에 따라 가중치 매개변수를 갱신하기만 하면 된다.


